Data
A newly imported program consists of bytes that have not yet been identified. These
bytes are known as undefined data and are displayed using "??". Disassembly,
analysis, and other user actions convert these bytes into instructions or defined
data. In general, the term "data" refers to defined data.
Data Types
Data is created by applying Data Types to bytes in
memory. Data Types interpret bytes as values and provide a visual interpretation of
those bytes based on the Data Type used, e.g., a four byte IEEE floating point number or a
two byte little endian
word. Ghidra comes packaged with a set of "Built-in" Data types (e.g., byte, word, float,
etc). Ghidra also provides the capability of creating "User-defined" Data types
(structure, array, typedef, etc) and supports dynamic data types whose structure depends on the
underlying data.
 It is important to note that the size of many of the primitive built-in types is
determined by the language and compiler specification (e.g., the size of an integer
can vary).
It is important to note that the size of many of the primitive built-in types is
determined by the language and compiler specification (e.g., the size of an integer
can vary).
Built-In Data Types
|
Undefined - Fixed Size Types
|
| Name
| Size
|
| undefined (default) |
1 |
| undefined1 |
1 |
| undefined2 |
2 |
| undefined3 |
3 |
| undefined4 |
4 |
| undefined5 |
5 |
| undefined6 |
6 |
| undefined7 |
7 |
| undefined8 |
8 |
Settings
- Mutability (normal, volatile, constant)
|
|
Numeric - Fixed Size Types
|
| Name
| Mnemonic
| Size
| Signed/Unsigned
|
| byte |
db |
1 |
Unsigned |
| sbyte |
sdb |
1 |
Signed |
| word |
dw |
2 |
Unsigned |
| sword |
sdw |
2 |
Signed |
| uint3 |
uint3 |
3 |
Unsigned |
| int3 |
int3 |
3 |
Signed |
| dword |
ddw |
4 |
Unsigned |
| sdword |
sddw |
4 |
Signed |
| uint5 |
uint5 |
5 |
Unsigned |
| int5 |
int5 |
5 |
Signed |
| uint6 |
uint6 |
6 |
Unsigned |
| int6 |
int6 |
6 |
Signed |
| uint7 |
uint7 |
7 |
Unsigned |
| int7 |
int7 |
7 |
Signed |
| qword |
dqw |
8 |
Unsigned |
| sqword |
sdqw |
8 |
Signed |
Settings
- Endian (default, big, little)
- Format (hex, decimal, octal, binary, ascii)
- Mnemonic-style (default, assembly, C)
- Mutability (normal, volatile, constant)
- Padding (unpadded, padded)
|
|
Miscellaneous - Fixed Size Types
|
| Name
| Mnemonic
| Size
| Signed/Unsigned
|
| void |
void |
0 |
n/a |
| wchar16 |
wchar16 |
2 |
Signed |
| wchar32 |
wchar32 |
4 |
Signed |
Settings
- Mutability (normal, volatile, constant)
|
Numeric - Dynamic Size Types
size determined by data organization within compiler specification - order is based upon relative sizes
|
| Name
| Signed/Unsigned
|
| char |
(determined by data organziation)* |
| schar |
Signed* |
| uchar |
Unsigned* |
| short |
Signed |
| ushort |
Unsigned |
| int |
Signed |
| uint |
Unsigned |
| long |
Signed |
| ulong |
Unsigned |
| longlong |
Signed |
| ulonglong |
Unsigned |
Settings (may vary)
- Endian (default, big, little)
- Format (hex, decimal, octal, binary, ascii)
- Mnemonic-style (default, assembly, C)
- Mutability (normal, volatile, constant)
- Padding (unpadded, padded)
*Additional character type Settings:
- Charset (defaults to US-ASCII if user settable)
- Render non-ASCII Unicode (all, byte sequence, escape sequence)
|
Miscellaneous - Dynamic Size Types
size determined by data organization within compiler specification
|
| Name
| Description
|
| wchar_t |
Signed Wide Character* |
| pointer |
Pointer to memory address (may refer to another data type) |
| float |
Floating point data |
| double |
Double-precision floating point data |
| longdouble |
Long double-precision floating point data |
Settings (may vary)
- Mutability (normal, volatile, constant)
|
User-Defined Data Types
|
User-Defined Data Types |
| Name
| Description
|
| structure |
Grouping of data types that are located consecutively
in memory |
| union |
Grouping of data types that share the same memory
location(s) |
| typedef |
An alias for an existing data type |
| enum |
A list of named integer constants |
| pointer |
A reference to an address (type information
optional) |
| array |
A specified number of consecutive data objects of the
same type |
| function definition |
A function signature tagged with a generic calling convention |
Applying Data Type
Data is created by applying a data type to undefined bytes in memory. There
are numerous ways to apply data types. A status message indicating whether or not data
was created is displayed in the tool's status area.
Regardless of how a data type is applied, data is
only created if the data type will fit within the available undefined bytes.
Drag from Data Type Manager
Use the Data Type Manager
to choose a data type from the set of available data types. To apply a data type from
the data type Manager:
-
Open the Data Type Manager (select
Window Data Type Manager)
Data Type Manager)
-
Select a data type from the Data Type
Manager
-
Drag the data type onto a single
address or selection in the Listing window
Cycle Groups
Cycle Groups are an easy way to apply basic data types (byte, word, float,
etc). A Cycle Group is a collection of similar data types that are commonly
associated together. Cycling a data type facilitates changing from one data type to the
next data type in the same group. When the last data type is reached, the cycle
restarts.
Each Cycle Group has an associated "hot key". Pressing the "hot key" cycles from the
current data type to the next one within the group. Ghidra provides the following
Cycle Groups:
| b |
Byte Word DoubleWord QuadWord
Byte |
| ' (single quote) |
Char String Unicode Char |
| f |
Float Double LongDouble Float |
To apply a data type from a cycle group:
-
Pick a basic data type to apply (for example double-word)
-
Place the cursor on the desired address or make a selection
-
Using the keyboard, press the associated "hot key" until the
data type appears ("b" in this case, 3 times) . In this example, the first time
"b" is pressed, a byte (db) will appear in the mnemonic field. The second time a
word (dw) will appear, and the last time a double-word (ddw) will appear.
-
If you pressed the "hot key" too many times and passed the data
type, continue pressing the "hot key" until you reach the data type again.
Favorites
A Favorite data type is a data type that you use frequently and want to apply
from the Data popup menu. By default Ghidra sets most commonly-used data types as
Favorites. However, any data type can be configured
to be a favorite.
To apply a favorite:
- Right click on cursor location or selection
- Select the Data popup submenu
- In the Data popup, select the favorite data type to be applied
 To quickly assign a key binding to a favorite,
use the Key Bindings
Shortcut. Key Bindings allow you to assign "hot keys" to any menu item.
To quickly assign a key binding to a favorite,
use the Key Bindings
Shortcut. Key Bindings allow you to assign "hot keys" to any menu item.
Recently Used Data Type
The last applied data type is always available at the bottom of the data menu. By
default, the "hot key" assigned to this option is 'Y'. This feature is a useful
shortcut for applying the same data type multiple times.
Clearing Data
Data and instructions can be cleared,
reverting them back to their undefined state.
To clear defined data back to an undefined state:
- Place the cursor on the defined data to be cleared
- Press mouse-right, and choose Clear code
bytes from the popup menu
 Deleting
data types from the Data Type Manager window is a quick way to clear every
instance of a data type in a program.
Deleting
data types from the Data Type Manager window is a quick way to clear every
instance of a data type in a program.
Changing Data Settings
Depending on the data type, data may have settings available which affect the way it is
displayed. For built-in data-types, the available settings are indicated in the table above. For example, the byte data type has a
format option which allows the user to have the data displayed as hex, octal, etc. The
available settings are defined in the Data Type Table above. Data
settings can be changed for an individual data item or for all data of the same data
type.
To change the settings of a single data item:
- Place the cursor on the data item
- Press mouse-right to bring up the popup menu
- Select Data Settings... to bring up the
settings dialog
In the screenshot above, the settings dialog is shown for a byte data type applied at
address 0x01007192. The dialog shows all the available settings for that data
type. For each setting, the dialog shows the setting name, value, and a checkbox
indicating whether or not the setting matches the default setting.
To change a setting, click on its value in the Setting column. This will display a
list of valid choices for that setting. Choose a value from this list of choices and
press OK. To reset a setting to its default value, set the Use Default
checkbox.
The default settings for a given data type can
be changed. When a default setting has been changed, every data item currently
using the default setting for that data type will use the new default value. Data items
that have a modified value for that setting will not be affected.
To change the default settings for a given data type:
- Place the cursor on a data item of that type
- Press mouse-right to bring up the popup menu
- Select Data Default Settings... to bring up
the default settings dialog
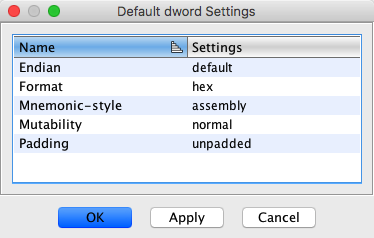
In the screenshot above, the default setting dialog is shown for the word data type.
The dialog shows all the available settings for that data type. For each setting, the
dialog shows the setting name and value.
To change a setting, click on its value in the Settings column. This will display a
list of valid choices for that setting. Choose a value from this list of choices and
press OK.
Default settings on components within a structure apply to that structure only. For
example, if Struct_1 has a byte component with its format set as Octal, then only other
instances of Struct_1 will be affected. Settings on other occurrences of byte are not
affected.
A typedef has the same set of settings as its underlying
data type. For example, when you create a typedef on a byte, the default settings on
the typedef will be the same as the original default settings of the byte. Changing the
default settings for either the typedef or its underlying data type doesn't affect the
default settings of the underlying data type or typedef respectively.
To change the data settings for multiple data
items:
- Select data items of interest (does not work for interior array elements)
- Press mouse-right to bring up the popup menu
- Select Data Settings... to bring up the
settings dialog
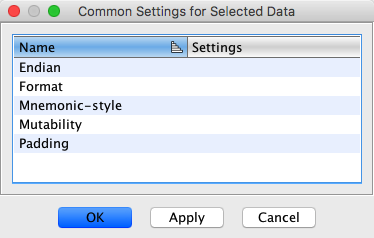
In the screenshot above, the common data settings dialog is shown for the current
selection. The dialog shows all the settings common to all defined data within the
current selection. For each setting, the dialog shows the setting name and value, where
the initial value is blank. Settings left blank will not be affected, allowing specific
settings to be changed without affecting others.
Creating Other Data Types
Structure
Ghidra provides two mechanisms to create and modify Structures. The Data
Type Manager can be used to create structures without applying them immediately.
It can also be used to edit them. Alternatively, structures can be created and
modified directly in the browser.
This document describes how to directly create, edit and apply Structures in the
browser.
Creating a new Structure
Creating a new structure in the browser uses previously defined data to define the
structure. The structure is created and applied at the same time. To create a
structure directly in the browser:
- Select a set of contiguous defined or undefined Data
- Use the right-mouse popup Data Create
Structure
- The Data items within the selection are used to define the structure
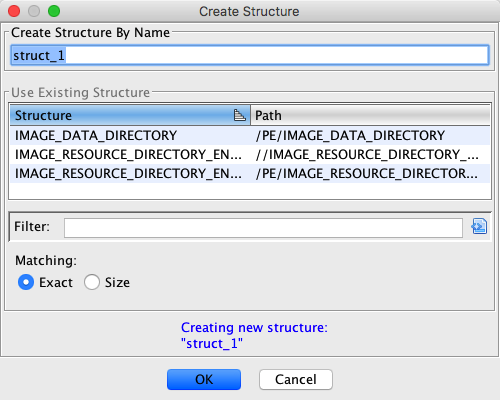
- The Create Structure dialog is displayed. This dialog can be used to
either create a new structure or apply an existing structure that has a matching
format. If a new structure is created, it will be added to the Data Type
Manager.
The Create Structure dialog is divided into two parts. In the top part is
used to provide a name if you are creating a new structure. It is initialized with
a default name. The bottom part shows a list of matching structures. You can
select from this list to use that structure instead of creating a new one.
The method for finding matching structures is either
by an exact match or by a match on structure size. You can change the type of matching
used by clicking the Exact or Size radio buttons under the Matching:
heading.
To create a new structure, enter a unique name in the Create Structure By Name
text field and press OK.
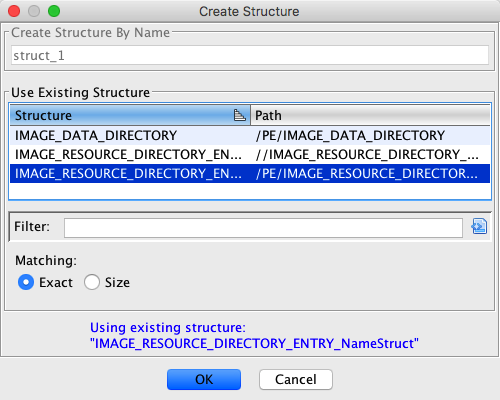
To use an existing, matching structure, find and select the structure in the Use
Exising Structure table and press OK.
You can create nested structures by following the
instructions above. The only difference is in Step (1), select contiguous bytes
within an existing structure.
Changing a Structure Name
- Place the cursor on the first line of the structure
- Press mouse-right over the structure and choose Data Edit Data Type...
- Change the name in the Structure Editor
Changing the name of a Structure member
There are two ways to rename a structure member. The first way is useful for
quickly changing the name of a single member:
- Right mouse click on a structure member in the Listing
- Choose the Data Edit Field...
action to bring the up the Edit Field Dialog
The second way is more useful for changing the names of multiple members. This method
will show the full Structure Editor:
- Place the cursor on the first line of the structure
- Press mouse-right over the structure and choose Data Edit Data Type
- Edit the field name for the structure member
Union
Unlike structures, unions can only be created using the Union Editor in the Data
Type Manager. Once a union has been created, it can be applied like any other data
type.
Enum
An Enum (Enumeration) data type is a C-style data type that allows the substitution
of a value for a more meaningful name. Enums are created from the Data
Type Manager using the Enum
Editor. When you apply the enum to a program, the name of the enum
appears in the mnemonic field and the named value corresponding to the byte at that location
appears in the operand field.
Example: Define an enum color with values red, green, and blue
assigned to 0x00, 0x01, 0x02 respectively. When you apply color to:
010062ab 01
?? 01h
the result is:
010062ab
01 color green
If the byte value is not one of the values defined in the enum, "Unknown value:
<value>" is displayed as the operand.
Pointer
A pointer data type points to another data type, including other pointers. Pointers can be
typed or untyped. Typed pointers specify the data type of the referred-to
location. By default, pointers have the same size as the size of an address for a
particular processor. For example, the pointers on a 32-bit processor will be 4 bytes
long.
To apply an untyped pointer:
-
Place the cursor over an undefined
data
-
Press the 'p' Quick-Key
- or -
Drag a Pointer data type from the Data Type Manager window
-
A default-sized pointer is created
-
If a valid address can be formed at the
location where you created the pointer, a reference is created to that address.
To create a typed pointer:
-
First create an untyped pointer
(described above)
-
Apply a data type to the untyped
pointer
-
The mnemonic will change from 'addr' to
the referenced data type's mnemonic (ie: for a byte "db *", for a pointer "addr *")
Pressing the 'p' key invokes the pointer action. This will generally create
a default pointer unless the existing data is already a pointer in which case that
pointer will be wrapped with an additional pointer (e.g., int * would become int **).
This action will always apply a default sized pointer.
Otherwise you can drag one of the other pointer types from the
Data Type Manager window.
With existing pointer data, the base type of that pointer may be changed simply by applying
another type onto the pointer (e.g., applying byte to default pointer becomes db *).
If you do not want this pointer stacking behavior to happen,
it is best to clear the code unit(s) before applying a data type via drag-n-drop or
key-binding actions.
To create a pointer of a specific size apply either
pointer8, pointer16, pointer32, or pointer64 to create a pointer sizes of 1, 2, 4, 8,
respectively.
Array
An array is a collection of data items of a single data type. The number of elements in
the array is specified when the array is created. Arrays can also be
multi-dimensional. In this case, the innermost dimension is created first.
To create an array,
- Place the cursor at the address where you want to create an array
- Create one data item of the base data type for the array. Any data type is valid,
including structures
- Press the '[' Quick-Key,
- or -
Press mouse-right on the data item and choose Data
Create Array
- A dialog will prompt you for the number of elements in the array. It will be
initialized with the maximum number of elements that will fit into the available undefined
bytes. It will also let you know the largest array you can make if you allow it to clear existing
data.
- Enter the number of elements in the array, and press OK
To create a multi-dimensional array:
- Create an array using the inner dimension for the number of elements
- Place the cursor over the new array
- Press the '[' Quick-Key,
- or -
Press mouse-right on the array and choose Data
Create Array
- Enter the number of elements for the next dimension, and press OK
- Repeat steps (3) and (4) until all dimensions have been created
Typedef
A typedef is an alias for another data type. It is useful for giving a more meaningful
name to a data type. For example, you might typedef dword to be
int.
In addition, a typedef may be based upon a pointer with additional Settings which can influence
how such a pointer should be interpretted.
Typedefs are created
using the Data Type Manager and applied like any other data type (See
Creating New
User Defined Data Types).
Void
A void data type can only be used as the return type (i.e., <RETURN> variable)
of a function and can be specified from
the Function Editor,
Set Data Type popup action menu,
as well as from the Data Type Manager using drag-and-drop.
String Data Types
A String consists of a sequence of characters and is generally terminated by a
null character ('\0') or has a length value prefixed before the string.
Characters in a string
The characters that make up a string can be encoded from bytes in a multitude of ways:
- Single bytes from the ASCII or other character set.
- 16 bit or 32 bit int values from the respective Unicode character sets.
- Variable length byte/int sequences that encode a single character, such as UTF-8
or UTF-16.
Size of a string
The extent of the string is determined by:
- Null terminating character ('\0').
- Containing field length (ie. fixed length strings, or length of an array of characters).
- Prefixed length value for Pascal strings.
Each Ghidra string data type will document if its null-terminated or fixed length or
pascal in its description or its type name.
The difference between null-terminated and fixed length strings is subtle. A null-
terminated string will extend until a null character is found (with a sanity check max of 16k),
regardless of the size of the field/structure that contains the string,
whereas a fixed length string's length is determined by its containing field, with trailing
null characters trimmed, but interior null characters preserved.
In practice, the user will be unable to create a null-terminated string in Ghidra
that exceeds its containing field/structure as the UI will size the containing field
to match the detected length of the null-terminated string. However, if the bytes that
make up the contents of the null-terminated string are changed, and the null-terminating
characters are overwritten, the string instance could use bytes from outside of its footprint
to construct itself. In this case the string will be displayed in red to indicate that
there is an issue.
Character sets
Character sets define how characters are represented as byte values, and how byte
values are converted into characters.
Not all byte values are valid character encodings, and may result in undecode-able
values - for example, byte values from 128..255 are not valid when using a US-ASCII
character set, but are valid when using IBM437.
When a invalid mapping is encountered, it will be represented as the Unicode
character '�', which will render on your screen with an OS and font specific
shape (it is called the "REPLACEMENT CHARACTER" and is typically encoded as [\uFFFD]).
The following character sets are always available:
- US-ASCII
- limited to values between 0-127.
- ISO-8859-1 (Latin 1)
- UTF-8
- variable length 1-3 byte Unicode encoding.
- only Unicode values greater than 007F cause multi-byte sequences,
otherwise indistinguishable from US-ASCII.
- UTF-16, UTF-16BE, UTF-16LE
- 2 byte Unicode encoding.
- variable length, 2 or 4 bytes
- UTF-32, UTF-32BE, UTF-32LE
Other character sets that are typically implemented in the Java JVM:
- IBM437
- old school extended ASCII.
- Windows-1252
- GB2312
- Chinese
- variable length 1-2 bytes
- Many many more...
Unicode Byte Order Marks (BOM)
Unicode strings can start with a special character that signals the endian-ness
of the string. The BOM character bytes will be FE FF (16 bit) or
00 00 FE FF (32 bit) if the string is big endian, otherwise it will be
FF FE (16 bit) or FF FE 00 00 (32 bit) if the string is little endian.
If the BOM is present, it will override the endian-ness of the binary that
contains the string.
Arrays of character elements
Arrays of character elements (ie. char[16]) are treated as fixed-length string data types.
Arrays of wide char data types (wchar, wchar16, wchar32) are treated as Unicode strings.
Creating string instances
When creating a String at a location, consecutive characters will be included
in the String until a null character ('\0') is encountered.
When applied to a selection, String data types absorb all bytes in the
selection into a single string ignoring terminators.
TerminatedCStrings, on the other hand, create multiple strings for the selected bytes,
beginning a new string at each terminator.
Settings for string instances
Each string instance has settings that can be customized to change the way the
string is decoded and how it is rendered when displayed.
- Charset
- Any of the currently available java.nio.charsets.
- Defaults to US-ASCII
- See charset_info.xml to customize display order or character size.
- Not available on string types that have "UTF*" or "Unicode" in the
name.
- Render non-ASCII Unicode
- all - attempt to render the character (display font may or may not provide it)
- byte sequence - show the bytes that make up the problematic character
- escape sequence - show as an escape sequence - "\u1234"
- Translation
- Toggles display of translated string value on and off.
- Same as popup menu action Data | Translate | Toggle show translated value.
Dynamic Data Type
Dynamic data types adapt to the underlying bytes to which they are applied. These
data types can only be created by writing
a new Java class. For example, an IP header packet that has a header, body, and terminator
might be a good candidate for writing a Dynamic data type. The header might specify the
length of the body. The Dynamic data type can change its size and structure based on the
information stored in the IP header.
The PE (Windows Portable Executable) data type is another example of a
dynamic data type that manufactures new data types. When you apply the PE data type, it
creates (1) a new category
(using the address as the name) in the program data type manager, (2) a structure for the DOS
header, and (3) a structure, PE, that contains the DOS header. In order for the PE data
type to be successfully applied, you must import a DOS program as binary file.. The size of the structure varies
according to the information in the program.
As a convenience, a structure or union field can be edited directly from the listing without
bringing up the entire structure or union editor. To edit a field, click anywhere on the line
displaying that field in the listing and then right click and select Data Edit Field... from the popup context menu.
Edit Field Dialog
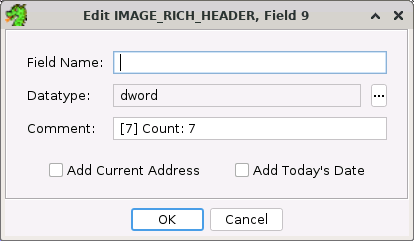
- Field Name: The name of the structure or union field can be changed here.
- Comment: The comment for the field can be entered or changed here.
- DataType: The data can be changed here. The text field is read only so you must
press the ... button to bring up the datatype chooser to change the datatype.
- Add Current Address: If selected, the current address where this field is edited
will be added to the datatype's field comment if not already there.
- Add Today's Date: If selected, the current date will be added to the datatype's
field comment if not already there.
If a default field (a field with an undefined
datatype (??)) is named or given a comment, the datatype will be set to undefined1 if
no specific datatype is set. This is because undefined fields are not stored and therefore
can't have an associated name or comment.
Provided By: Data Plugin
Related Topics: