Import File
This action is used to import a single file into Ghidra. If the file is an archive consisting of multiple programs, then this action will bring up the Batch Importer Dialog, otherwise it will use the standard single file Importer Dialog to complete the import.
Steps:
- Invoke the action from the File
Import File... menu item.
- Select the file to import using the filechooser that appears.
- Use the Importer Dialog (or the Batch Importer Dialog if it is an archive) that pops up to perform the import.
- Press OK from the Importer Dialog to perform the import.
- A results summary dialog will appear and, if successful, the new program will appear in the project window and if initiated from a CodeBrowser tool, it will be opened in the tool.
Alternative Steps (drag-and-drop):
- Project Window: Drag a file from the system file explorer application and drop onto the Ghidra Project Tree destination folder. Dropping onto the table view is not supported. In the case of Ghidra Zip File (GZF) or Ghidra Data Type Archive (GDT) file imports, an immediate unpack can be performed wthout a popup dialog if the Front End option Enable simple GZF/GDT unpack is enabled ( Edit
- or Running Tool: Drag a file from the system file explorer application and drop onto a Tool window (e.g., Code Browser Tool).
- The Importer Dialog (or the Batch Importer Dialog if it is an archive) will be displayed to complete the import.
- Press OK to initiate the import.
- A results summary dialog will appear and, if successful, the new program will appear in the project window and if initiated from a CodeBrowser tool, it will be opened in the tool.
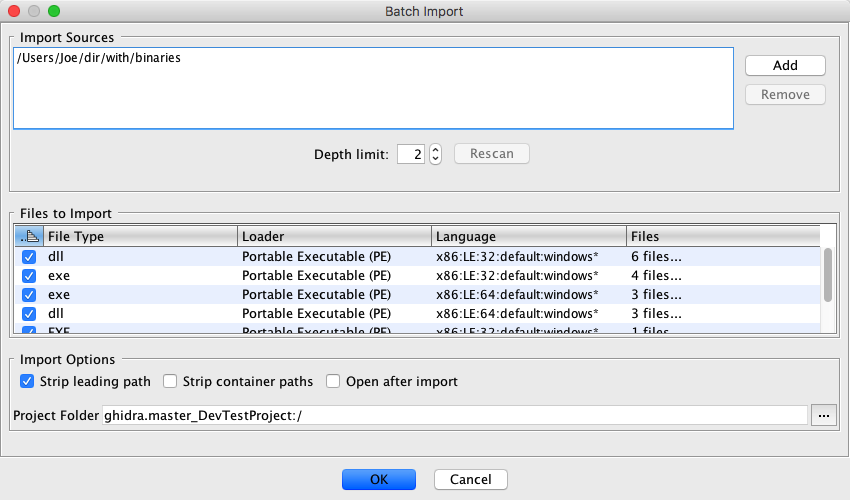
Batch Import
This action is used to import multiple files by selecting a root directory and letting it recursively find programs to import.
Steps:
- Invoke the action from the File
- Use the filechooser dialog that appears to select a root directory for searching for files to import.
- Use the Batch Importer Dialog that appears to select and configure files for importing.
- Press OK on the dialog to initiate importing the selected files.
- A results summary dialog will appear and, if successful, the new program(s) will appear in the project window. If the action was initiated from the CodeBrowser tool and only a few files were imported, they will be opened in the CodeBrowser tool.
Open File System
This action is used to open the File System Browser which can be used to view the contents of container files (tar, zip, etc.) and import files from within those containers.
Steps:
- Invoke the action from the File
- Use the dialog that appears to browse the contents of the container file and import files as desired.
Add to Program
This action is used to import data from a file into an existing program. The program must be open in the tool to perform this action.
Steps:
- Invoke the action from the File
- Use the filechooser dialog that appears to select a root directory for searching for files to import.
- Use the Importer Dialog to configure the import.
- Press OK on the dialog to initiate importing the selected files.
- When the import is complete, the currently open program should have additional data in it.
Load Libraries
This action is used to load libraries into the project and link them to an existing program. The program must be open in the tool to perform this action.
NOTE: If you know at the time of import that you want to load/link libraries, it is preferred to set the library loading options directly from the Importer Dialog's Options... button.
Steps:
- Invoke the action from the File
- Use the options dialog that appears to control the library import settings.
- Press OK on the dialog to initiate importing any discovered libraries.
- When complete, the currently open program should have additional External Programs linked if matching libraries were found.
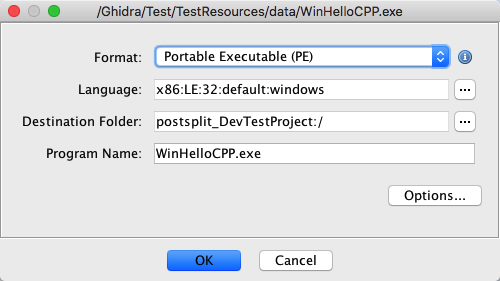
 If this dialog appears as a result of the
Add To Program action, then the Language, Destination Folder, and Filename fields
will be disabled since these values are already determined by the existing program.
If this dialog appears as a result of the
Add To Program action, then the Language, Destination Folder, and Filename fields
will be disabled since these values are already determined by the existing program.
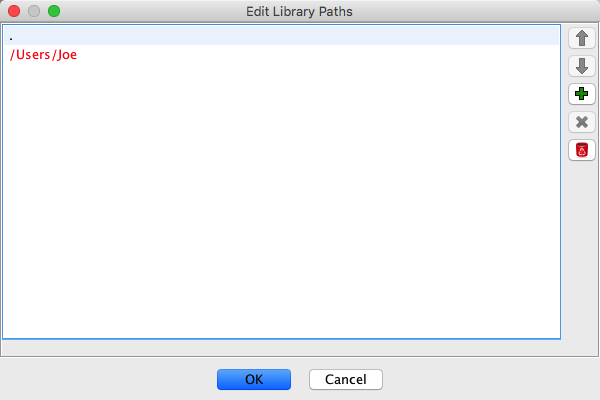
 button to move the path up in
the list
button to move the path up in
the list button to move the path down
in the list
button to move the path down
in the list button
button The newly added path will be placed at
the top of the list.
The newly added path will be placed at
the top of the list. button
button This option will remove any paths added manually.
This option will remove any paths added manually.