To bring up the explorer, select Window -> Function Bit Patterns Explorer from the Code Browser.
Data Sources
Current Program
Use the "Gather Data from Current Program" button to gather data to analyze from the current program. You can also select Tools -> Explore Function Bit Patterns in the Code Browser.
Directory of XML Files
Use the "Read XML Files" button to select a directory of XML files containing data from windows around function start/returns (one XML file per program). To generate these XML files, run the script DumpFunctionPatternInfoScript.java
Data Gathering Parameters
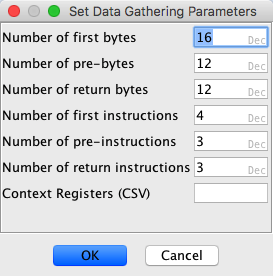
Several parameters control how much data is gathered around each function. When analyzing a single program, a dialog will pop up which allows you to enter values for these parameters. When running the script DumpFunctionPatternInfoScript.java you can set these parameters by editing the file DumpFunctionPatternInfoScript.properties. The parameters are:
Number of First Bytes
The number of bytes to gather starting at the entry point of the function.
Number of Pre-Bytes
The number of bytes to gather immediately before (but not including) the entry point of a function.
Number of Return Bytes
The number of bytes to gather immediately before (and including) a return statement in a function.
Number of First Instructions
The number of instructions to gather starting at the entry point of a function.
Number of Pre-Instructions
The number of instruction to gather immediately before (and not including) a function start.
Number of Return Instructions
The number of instructions to gather immediately before (and including) a function start.
Context Registers
The context registers whose values you wish to record. Enter a comma-separated list of registers into this field. For example: TMode,LMode
Reasonable starting values for the parameters controlling the number of instructions to be gathered are 3, 4, and 5. When setting the number of bytes to gather, it's reasonable to choose a value that can hold most of the corresponding instruction sequences. For example, suppose you're examining x64 programs and set the number of first instructions to gather to 4. A reasonable number of first bytes to gather is 20, which should be enough to hold most 4-instruction sequences (even though the maximum length of an instruction on x64 is 15 bytes).
Recommended Parameters:
Data Views
The main interface of this plugin is a panel with multiple tabs. All tabs, except for the Pattern Clipboard tab, are auto-populated, either after reading a directory of XML files or clicking "OK" on the Data Gathering Parameters dialog.
Each tab displays a different view of the gathered data:
Byte Sequence Tabs
There are three byte sequence tabs: one for first bytes, one for pre-bytes, and one for return bytes. Two types of filters can be applied to byte sequences: length filters and context register filters. Length filters are required, but context register filters are optional.
Length Filters
A length filter requires two pieces of data: a minimum sequence length and a prefix/suffix length. The filter filters out all sequences which do not meet the minimum length constraint. For each sequence that does meet the constraint, it takes either a prefix or a suffix of a appropriate length (suffixes are specified as a negative number in the input dialog for the filter data).
Context Register Filters
These allow you to filter sequences by specifying values for some or all of the tracked context registers.
Note: Filters for byte sequences are not shared between tabs.
After applying such a filter, there will be a table containing bytes sequences, all of which have the same size. Select some rows in the table, right click, and select Analyze Sequences to look for patterns.
Instruction Sequence Tabs
Similar to byte sequences, there are three instructions sequence tabs, containing first instructions, pre instructions, and return instructions, respective. These sequences are sorted into a tree. Note that the length of an instruction is taken into account. For example, sequences which begin with a one-byte PUSH instruction will go through a different path in the tree than sequences with begin with a two-byte PUSH instruction. There are two optional filters which you can apply to instruction sequences:
Percentage Filters
Filtering by X% will remove a node from the tree if the percentage of paths going through the node is less than X%.
Context Register Filters
These allow you to filter sequences by specifying values for some or all of the tracked context registers.
Note: Filters for instruction sequences are not shared between tabs.
If you hover over a node, you can see the percentage of all paths in the tree which go through that node. To search for patterns in the byte sequences corresponding to a given node, right click on the node and select Analyze Sequences.
Function Start Alignment Tab
This tab displays with n rows, where n is the specified alignment modulus. The number in row i is the number of functions whose addresses modulo the alignment modulus is equal to i. This allows you to determine whether function starts are aligned within the program (for example, on x64, compilers will frequently 16-byte align function starts at higher optimization levels). If you know that functions are aligned along a certain boundary, you don't have to search for function starts in the non-aligned bytes.
Context Register Information Tab
This tab displays all values recorded for the context registers you specified.
Pattern Clipboard
You can send patterns you find to the pattern clipboard for evaluation. In the clipboard, there are two types of patterns: PRE and POST. PRE patterns correspond to patterns that occur before the start of a function. Patterns from pre-byte and pre-instructions sequences are considered PRE patterns, as are patterns from return byte and return instruction sequences (the idea being that the return is followed by the start of another function). Patterns from first byte and first instruction sequences are considered POST patterns.
You can edit the "Alignment" column in the pattern clipboard. The context register column is populated from context register filters applied while exploring the data.
Evaluating Patterns
You can evaluate a selection of patterns in the clipboard by selecting them, right-clicking, and performing the "Evaluate Selected Patterns" action. This will search for the patterns in the current program (if there are both PRE and POST patterns, they will be combined). A table will pop up which displays all of the matches, information about each match, and aggregated information about all of the matches.
Clipboard Buttons
The Pattern Clipboard tab has several buttons, which allow you to:
- Create Functions from the selected patterns.
- Export selected patterns to a pattern file. Such files can be used by the Function Start Analyzer during Auto Analysis. A dialog will appear asking for two values: Total Bits and Post Bits. When the Function Start Analyzer reads in a pattern file, it makes a set patterns. This set consists of each PRE pattern concatenated with each POST pattern for which the concatenation has at least Total Bits fixed bits, at least Post Bits of which much be after the PRE bits.
- Import patterns from a pattern file. Note: You should only do this with files generated by this plugin. Arbitrary XML files from the Processors directory may contain attributes not supported by this plugin.
Analyzing Byte Sequences
Byte sequences to analyze are displayed in a table along with information about each sequence, such as the number of occurrences the sequence or (possibly) the disassembly of the sequence. You can make a selection of rows in this table, right-click, and perform the following actions:
Send Selected to Clipboard
This will send the selected sequences to the Pattern Clipboard.
Merge Selected Rows
This will merge the selected sequences into one sequence. For a given bit position in the merged sequence, if all selected sequences agree on that position the merge will contain that value, otherwise it will contain a dit in that position.
Send Merged to Clipboard
If you've merged a select of sequences, there will be an action to send the merged sequence to the pattern clipboard.
Mine Sequential Patterns
If the sequences you're analyzing came from a byte sequence tab, there will be an action to Mine Sequential Patterns.
Mining Closed Sequential Patterns
A Closed Sequential Pattern is a pattern such that no proper super-pattern occurs more frequently in the sequences that you're analyzing. For example, suppose the sequence "111" occurs ten times. Then the sequences "11.", "1.1", and ".11" also occur (at least) ten times. We'd like to avoid a combinatorial explosion of patterns; restricting to closed patterns ensures that any sub-patterns which are listed are strictly more common than the main pattern.
Before actually running the mining algorithm, a dialog will appear which asks you to set some parameters:
Minimum Support Percentage
The algorithm will only return patterns which occur in at least this percentage of the data being analyzed.
Minimum Number of Fixed Bits
Any pattern returned by the algorithm will contain at least this many non-ditted bits.
Binary Sequences vs. Character Sequences
This allows you to treat sequences as either sequences of characters (nibble) or sequences of bits. If bit sequences take too long to mine, you can try the character sequences option, which will find fewer patterns but will run much faster.
Note: The longer the algorithm runs, the faster the progress bar will advance, so don't be too dismayed if it initially seems to be taking a lot of time.