REshare Ramblings - Bad Vibes with IDA
At r2con2025 I accidentally presented REshare, a JSON-based format and associated tools for exchanging reverse engineering knowledge between various tools. Today - after focusing Ghidra, my "home ground" - I'm releasing the IDA importer, which raises my confidence in that the whole concept can actually work in the long run.
The presentation was "accidental", because originally I wanted to only talk about r4ghidra, but along the way I ended up stepping up an abstraction layer (as I often do, not always wisely) and started to solve problems for all tools instead of just two of them. This resulted in stepping out of my comfort zone in multiple directions, yielding some lessons learned that I'd like to share in the following, loosely associated sections.
Overview
In case you are curious about the REshare-specific parts of the talk, here's a short summary:
REshare defines a serialization format for reverse-engineering information such as reversed symbols, types and comments. The format is JSON-based so it remains accessible to humans, while you'd have standard tools to manage (e.g.: put it in Git, use your favorite formatters) and even transform it (e.g.: with jq). The format is defined using JSON Type Definition from which you can generate serializers and deserializers for multiple languages.
The idea is to implement importers and exporters based on the generated serializers for our favorite tools (or formats) so information can be exchanged between all of them. With N tools this should be O(N) effort, while building bridges across all tools would be O(N^2) (see also git fast-export).
The current support graph looks like this:
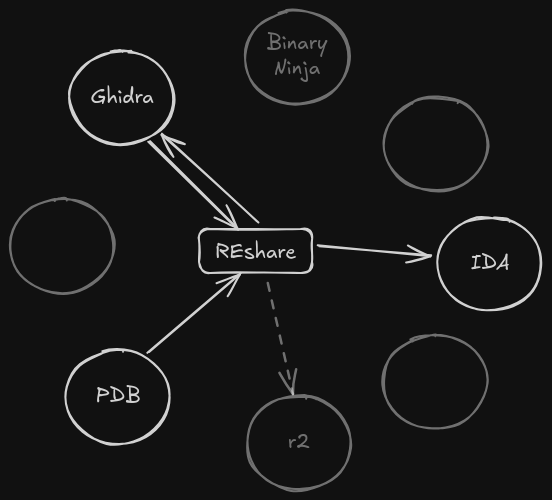
Prototypes and Second Prototypes
Current implementations of REshare focus on data types, as these are fundamental to understand the semantics of a program. Types are also hard, compared to address-metadata pairs like symbols or notes:
- Types (structures) can embed each other ("composite" types).
- Types can contain direct and indirect circular references (e.g.: linked list nodes)
- Types are represented differently across tools
- In case of PDB, unions inside structures may be "inlined" into the structure placing N members at the same structure offset.
- IDA refuses to register types with doubly allocated offsets but doesn't tell what the problem is.
- Function signatures are types with potentially architecture-specific details (e.g.: register use for parameter passing - REshare doesn't handle these yet)
- ...
The good news is that so far, the REshare data structure can describe quite complex data types of Windows and importing into Ghidra and IDA works1 too.
The better news is that working on different tools allowed me to do what all programmers dream of: rewriting stuff from scratch! It's reassuring that the general structure of import and export code remained generally the same for all implementations, although it's possible my brain got anchored to my initial, bad design. At least the basic principles are now somewhat documented.
While REshare supports several languages, implementation is currently exclusively in Python. I had a strong desire to move to strictly typed languages after I made the mistake of writing the PDB exporter without type hints. But with typing and a proper IDE, the code is easy to navigate, and so far all exporters/importers are done in less than 400 LoC. While this number will certainly go up as we add support for more kinds of data, this magnitude of complexity should be comfortably handled by anyone wishing to tweak the code to their needs.
Tweaking was the main reason I stuck with Python: I want REshare to support use-cases when source and target databases don't line up perfectly (e.g. IDA vs. Ghidra auto-analysis differ), and custom error correction/heuristics are required. An obvious example is symbol porting across multiple binary versions, where addresses won't match and there may be missing and extra code as well.
In the long run we may end up with some configuration file, or even a GUI, but for now encapsulating tool-specific APIs in a few functions is good enough for me. Because there be dragons...or genius countesses of the 19th century!
[1] On my machine, with my targets at least
Types in the IDA API
At r2con someone mentioned their difficulty in navigating Ghidra's Javadoc. This is a common complaint with Java projects and I can remember the dread I felt as an intern when I first had to understand a rather complex system based on generated Javadoc only. But years have passed and Javadoc became natural for me, and I can only encourage those who feel lost: if intern me could figure it out, so can you! :)
When I tuck up my sleeve to write the first 400 LoC for IDA I was more concerned whether I'd find some catastrophic flaw in my Ghidra import/export while implementing it again from scratch for a different tool. Fortunately that wasn't case, but I struggled a lot in the end nonetheless.
You see, IDA technically has API documentation, but that doesn't really matter if your docstrings are the corresponding function names translated to natural language, but explain nothing about arguments, return values, not to mention error conditions.
So, in case you are a lost soul wandering IDA's type info API, here's what I figured out for version 9, based mostly on the samples provided bundled with IDAPython (everything else was mostly wrong, as I'll explain in a bit):
- Data types are represented by
tinfo_tobjects. - You can transform these objects to represent specific data type-types (pointers, structs, enums, etc.) by invoking the relevant
.create_XXX()method on them. - Since the IDAPython API often expects a single, arbitrarily typed
*argsargument, type hints will tell you lies, such as.create_enum()can't be called without an argument.- Errors are signaled by returning
False, or the library simply crashing with an "internal error [UNDOCUMENTED ERROR CODE]". In case of composite types this is likely the result of overlapping or otherwise messed up member offsets - I suspect this is why examples use the.push_back()method to add members, and automatically calculate their position.
- Errors are signaled by returning
- So far so good, but your type still doesn't have a name!
tinfo_t("name")doesn't instantiate a named type, but tries to look upname. You should use no arguments for instantiation..get_named_type("name")resets the object to atypedefeven if thetinfo_tobject was already loaded with a bunch of juicy info about some complex type. We actually use this behavior so we can have named types required for creating circular references without knowing how the final type will look like!ida_typeinf.get_named_type("name")on the other hand works much like thetinfo_t("name")constructor, retrieving an already "saved" data type. Careful with namespaces, kids!.set_named_type(None, "name")is what you are looking for! The first argument is the type library to add the type to,Nonemeans default.
- I couldn't figure out what
.save_type()does. The moment you issue.set_named_type(), the new data type appears in your type info library. While you import data in bulk you must be aware that AFAIK IDB's don't handle transactions, so you'll probably end up with a bit of a mess if something goes wrong during the last mile.
At this point you could rightfully ask: why didn't you just ask The AI for the solution? To answer that, I'll need a whole new section!
Vibe Coding in Reverse
I originally wanted to write this up while wrestling with Ghidra's decompiler API, but the work with IDA made some of the problems even more apparent. The core of the issue must be that developing RE tools is a very niche area, with relatively little code available for training:
- Hallucinated APIs are everywhere. My theory here is that the LLM is guided more by how the user wants the API to look like (implied by the prompt) rather than how the API actually looks like, based on the relatively little factual information available in the model.
- An example I took note of is that Ghidra has abstractions like
HighVariableandHighSymboland it's not easy to keep in mind which does what. Remarkably, machines should be good at this (source code+docs are available) yet with LLMs we seem to give up this advantage, because they tend to "forget" these gory details as easily as I do.
- An example I took note of is that Ghidra has abstractions like
- Hallucinations render resulting code almost always useless, because one API is hallucinated and then none of the later code makes sense. One could argue, that agentic setups help with this by e.g. attempting compilation, but...
- ... APIs change, especially in case of IDA - this is why you don't see plugin developers until a week after a major release, when they come out of their cabins with uncombed facial (and/or other) hair. This is bad, because:
- information about the old API actively misinforms the models about the current state of the world
- getting new information to models means training which is expensive (and repeated inference is not cheap either!)
- in a niche area like RE tools the API may become obsolete before you have enough training data in the first place
- I was positively surprised to find when LLMs admitted that they can't do something, as I expected them to make up bullshit solutions instead. On the flip-side they refused to provide me with the source of their negative conclusion, which is understandable, as I know the problem was solvable: for example the model inferred that getting the type for a decompiled Ghidra variable is simply impossible, while I could clearly see on my screen that this information is provided by Ghidra (and no, you don't need complex data-flow tracking - but this is a topic for another post).
Needless to say, I quickly gave up LLMs and ended up solving problems with my brain made of rotting flesh. This certainly caused a lot of cursing, but at least now I dusted down my IDA API skills so I can better see the differences and similarities of at least two major reversing tools. Comparison will certainly help me in making better design decisions for REshare to reduce breaking changes to minimum in the long run.
I'm still looking for REshare contributors, especially for Binary Ninja and radare2 tooling. Testing and bug reports are also much appreciated! Every new integration is a significant improvement to the overall usefulness of REshare, and who knows, maybe you can even demonstrate that I'm holding LLMs wrong and new importers and exporters can in fact be vibe coded! ;)